写在前面
本文中的内容并非完全原创,主要来源见文末的参考链接,本人仅作整理工作,用以记录自己的学习过程,由于个人水平有限,故部分内容可能会出现错误,还请包涵
思维导图
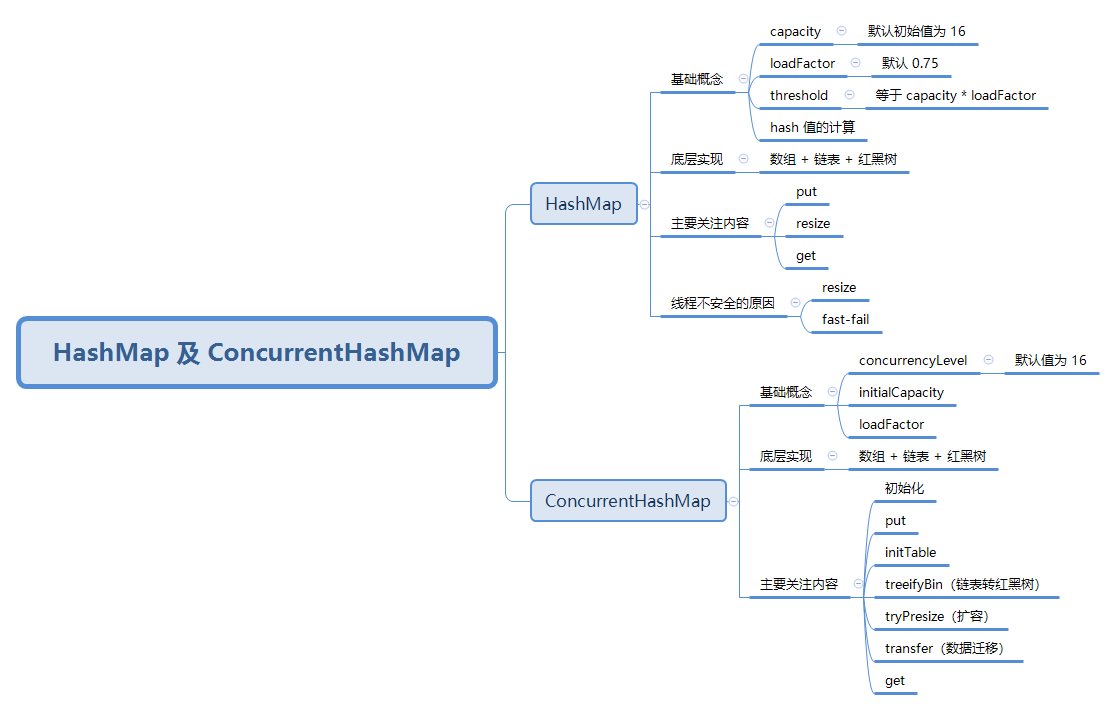
HashMap
由数组 + 链表 + 红黑树组成
HashMap 中 Node 的 key、value 值均可为null
在 Java8 中,当链表中的元素超过了 8 个以后,会将链表转换为红黑树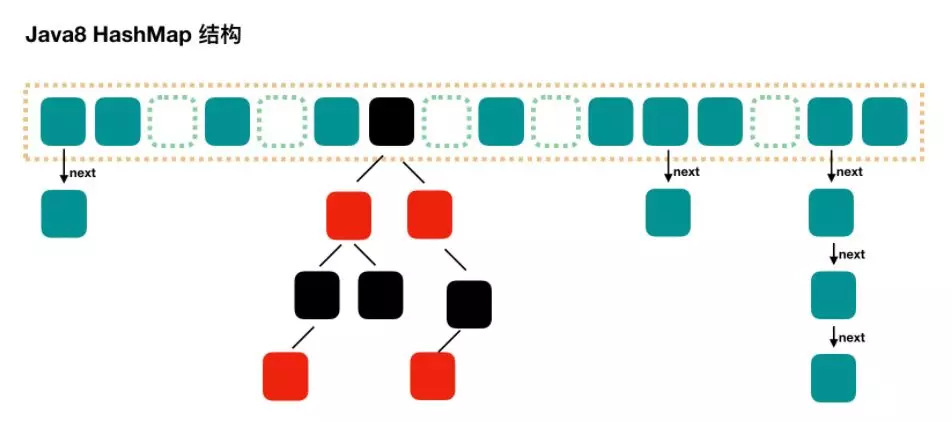
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode
- 链表中的 Node 节点实现了 Map.Entry<K, V> 接口,而红黑树中的 TreeNode 继承自 LinkedHashMap.Entry<K,V> 类,而 LinkedHashMap.Entry<K,V> 类又继承自 HashMap.Node<K,V> 类。即 TreeNode 是 Node 的子类
HashMap 中重要的属性
transient Node<K,V>[] table : 存储 Map 键值对元素的数组
capacity() : 当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍
loadFactor : 负载因子,默认为 0.75
threshold : 扩容的阈值,等于 capacity * loadFactor
hash
1 | static final int hash(Object key) { |
为何如此计算 hash 值暂不清楚
put
Java7 是在链表头部插入新节点,Java8 在链表尾部插入新节点
Java7 是先扩容后插入新值的,Java8 先插值再扩容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 第三个参数 onlyIfAbsent 如果是 true,那么只有在不存在该 key 时才会进行 put 操作
// 第四个参数 evict 我们这里不关心
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 第一次 put 值的时候,会触发下面的 resize(),类似 java7 的第一次 put 也要初始化数组长度
// 第一次 resize 和后续的扩容有些不一样,因为这次是数组从 null 初始化到默认的 16 或自定义的初始容量
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 找到具体的数组下标,如果此位置没有值,那么直接初始化一下 Node 并放置在这个位置就可以了
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {// 数组该位置有数据
Node<K,V> e; K k;
// 首先,判断该位置的第一个数据和我们要插入的数据,key 是不是"相等",如果是,取出这个节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果该节点是代表红黑树的节点,调用红黑树的插值方法,本文不展开说红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 到这里,说明数组该位置上是一个链表
for (int binCount = 0; ; ++binCount) {
// 插入到链表的最后面(Java7 是插入到链表的最前面)
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// TREEIFY_THRESHOLD 为 8,所以,如果新插入的值是链表中的第 9 个
// 会触发下面的 treeifyBin,也就是将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 如果在该链表中找到了"相等"的 key(== 或 equals)
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 此时 break,那么 e 为链表中[与要插入的新值的 key "相等"]的 node
break;
p = e;
}
}
// e != null 说明存在旧值的 key 与要插入的 key "相等"
// 对于我们分析的 put 操作,下面这个 if 其实就是进行 "值覆盖",然后返回旧值
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果 HashMap 由于新插入这个值导致 size 已经超过了阈值,需要进行扩容
// 由此可以看出 JDK 1.8 中 HashMap 是先插入元素再判断是否进行扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
数组扩容 resize
1 | final Node<K,V>[] resize() { |
get 过程分析
计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
遍历链表,直到找到相等(==或equals)的 key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个节点是否为所需
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
// 判断是否是红黑树
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 链表遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
remove
remove 方法有两个重载版本,本人将其定义为“强匹配”(key 和 value 都匹配)和“弱匹配”(key 匹配即可),接下来只针对“弱匹配”分析,“强匹配”大同小异
remove 的基本思路是通过 key 的 hash 值得到其在 table 中的 index 值,然后对该 index 位置上的链表或树进行查找,若找到则删除且返回旧值(旧值可以为 null),找不到则返回 null
源码如下1
2
3
4
5
6
7
8public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
1 | // matchValue 为 false 则代表“弱匹配” |
HashMap 中的红黑树
HashMap 线程不安全的原因
主要体现在 resize 时的死循环及使用迭代器时的 fast-fail 上
单线程 resize
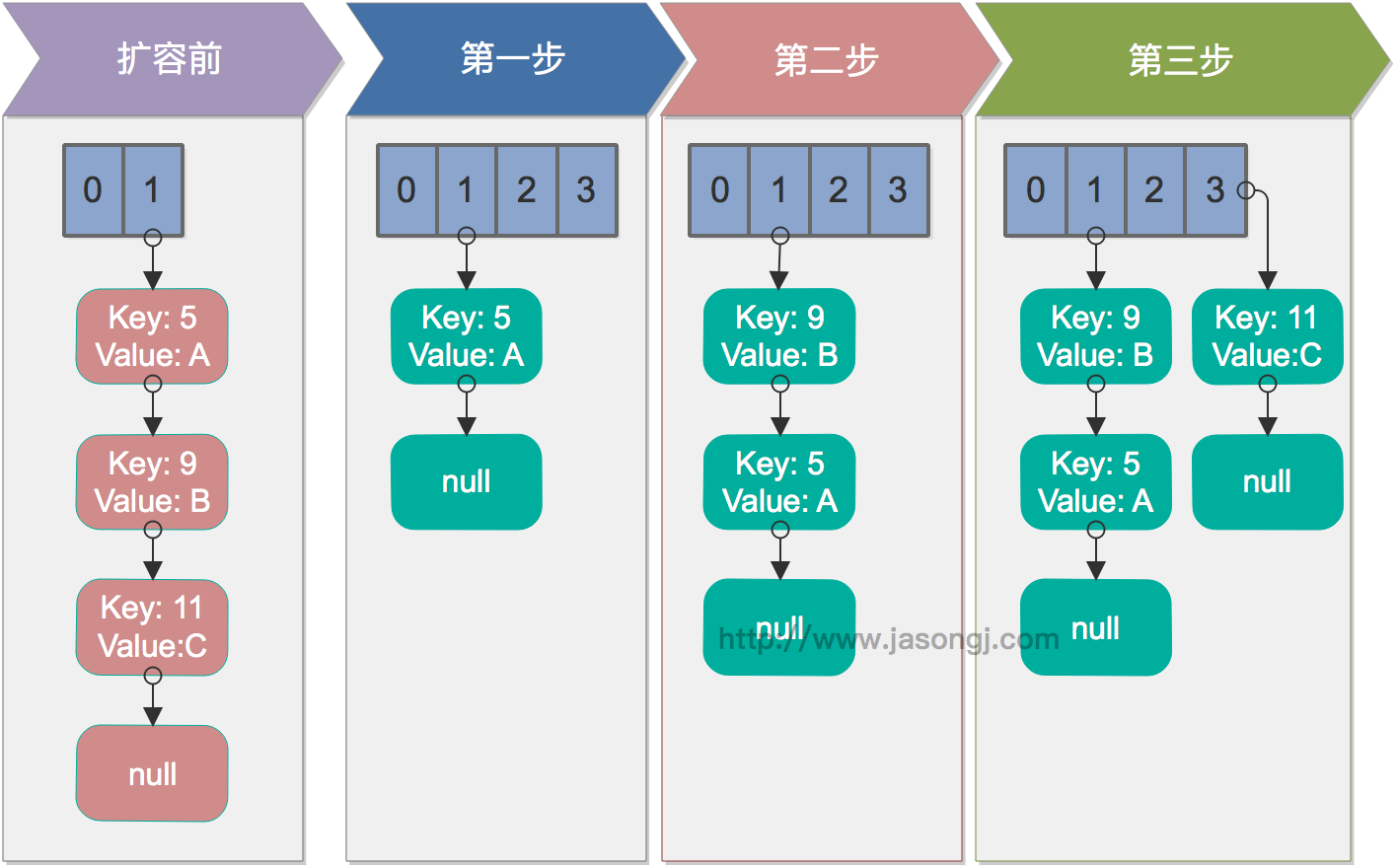
多线程并发下的 resize
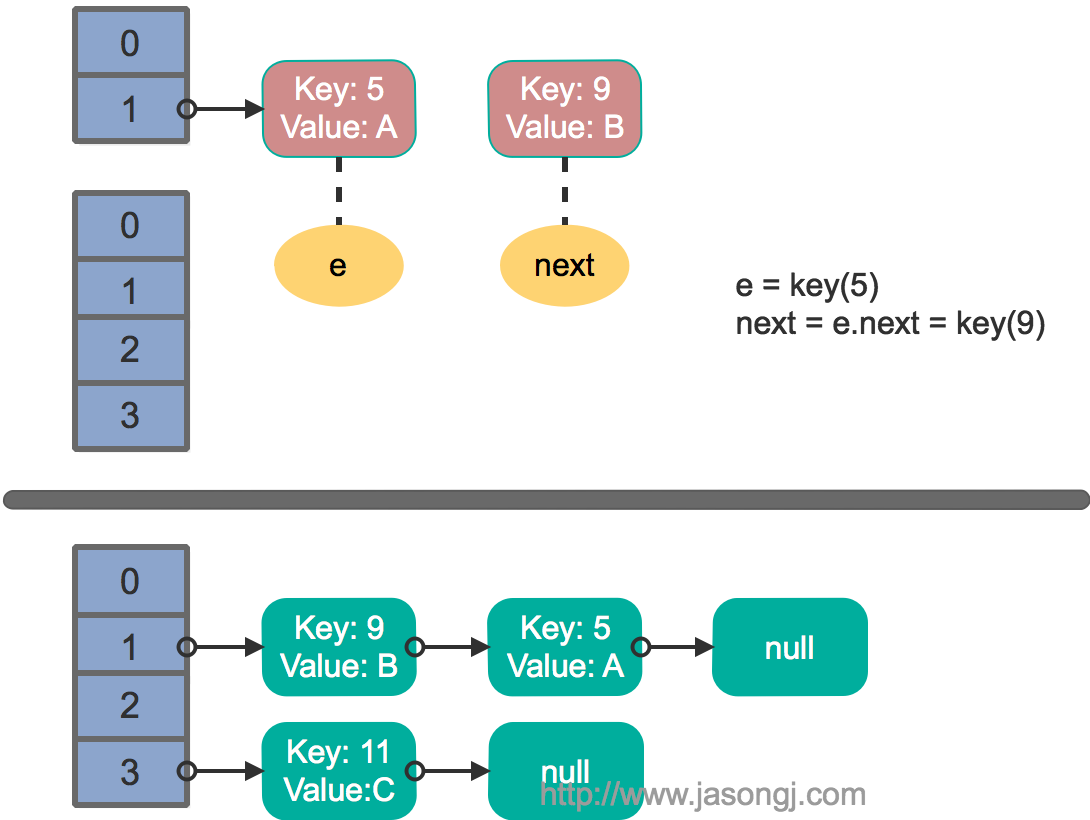
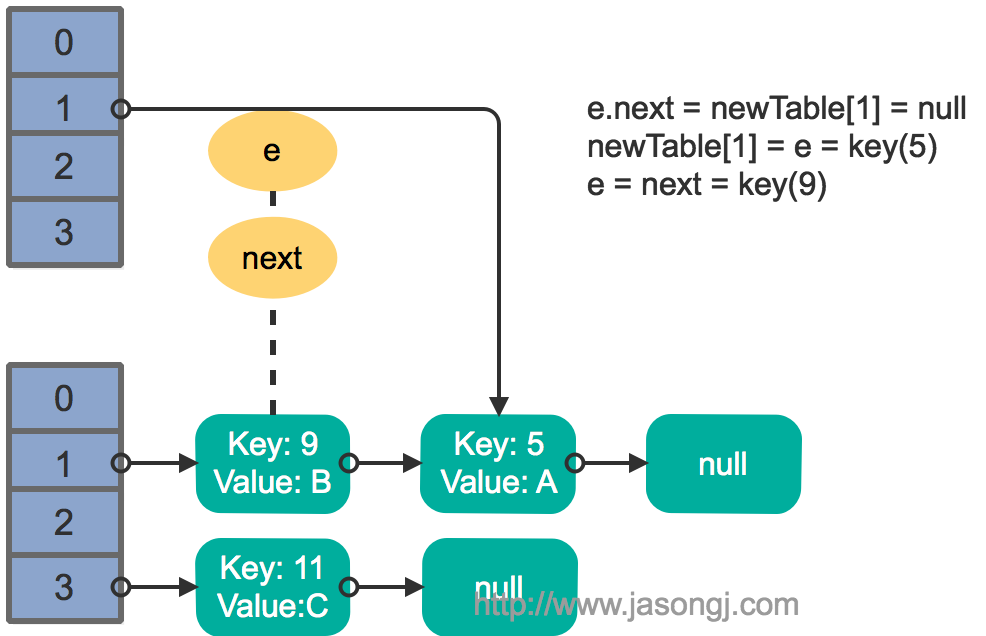
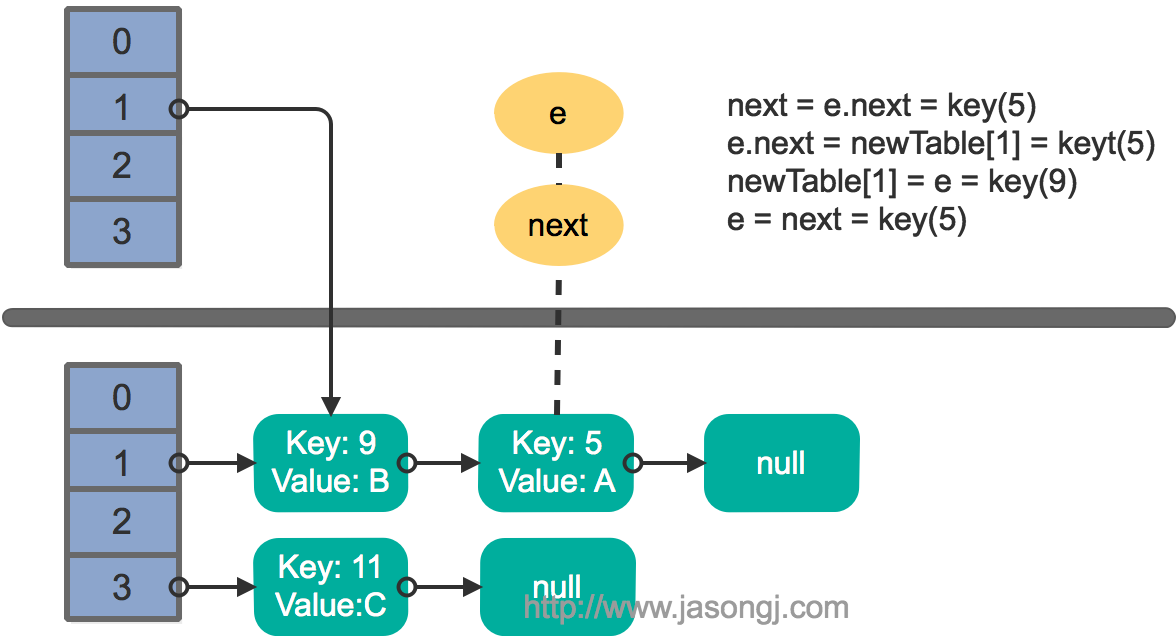
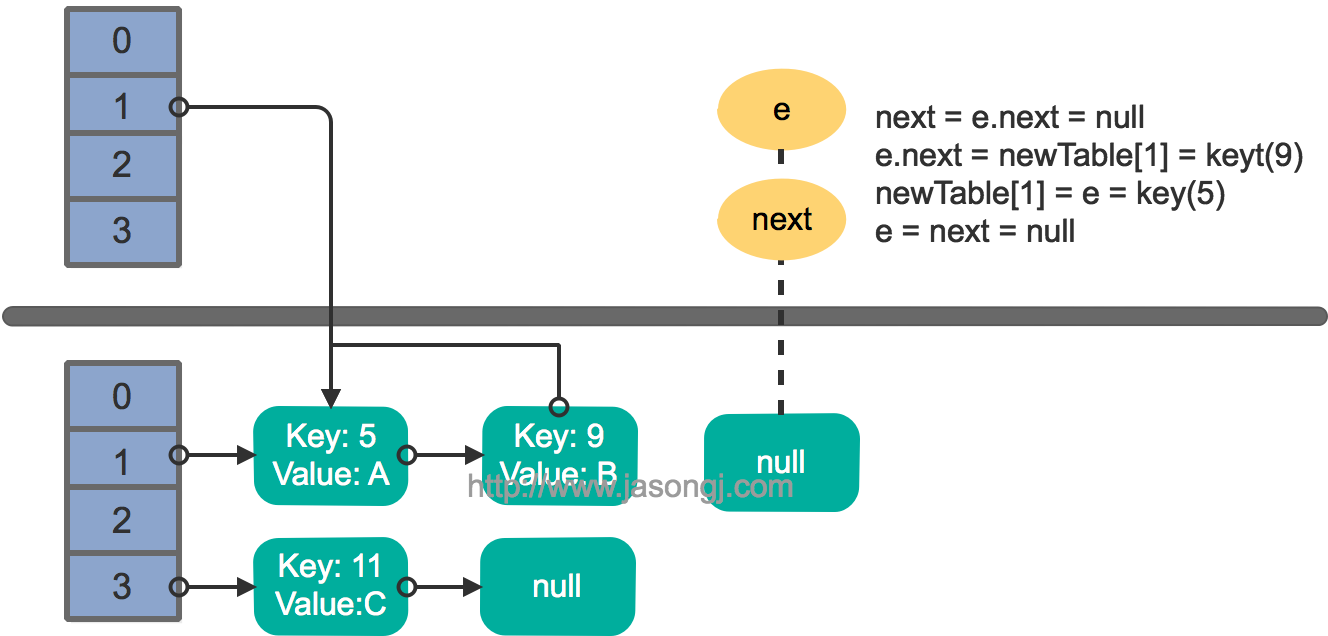
至此出现循环链表
Fast-fail
产生原因
在使用迭代器的过程中如果 HashMap 被修改,那么 ConcurrentModificationException 将被抛出,也即 Fast-fail 策略
通过判断迭代器自己的 modCount 和 HashMap 的 modCount 是否相等来判断是否在迭代的过程中 HashMap 经过修改
线程安全解决方案
需要保证只通过 HashMap 本身或者只通过 Iterator 去修改数据,不能在 Iterator 使用结束之前使用 HashMap 本身的方法修改数据
多线程条件下,可使用 Collections.synchronizedMap 方法构造出一个同步 Map,或者直接使用线程安全的 ConcurrentHashMap
Java8 ConcurrentHashMap
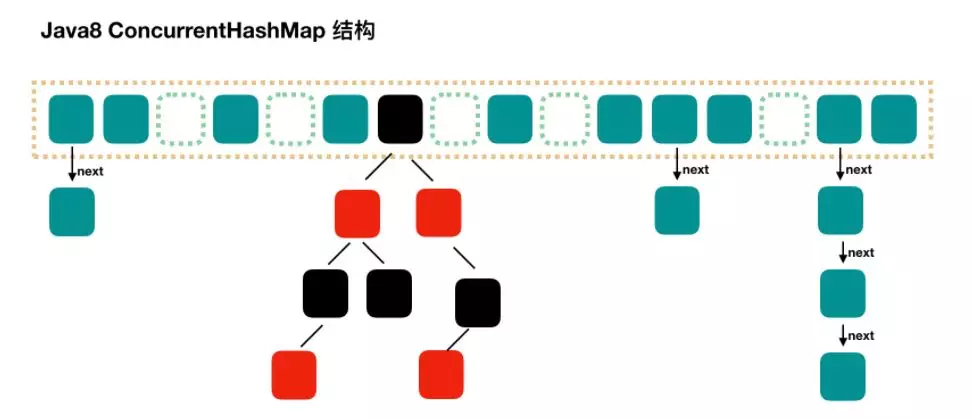
Java7 ConcurrentHashMap
采用锁分段机制
简单地说,ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全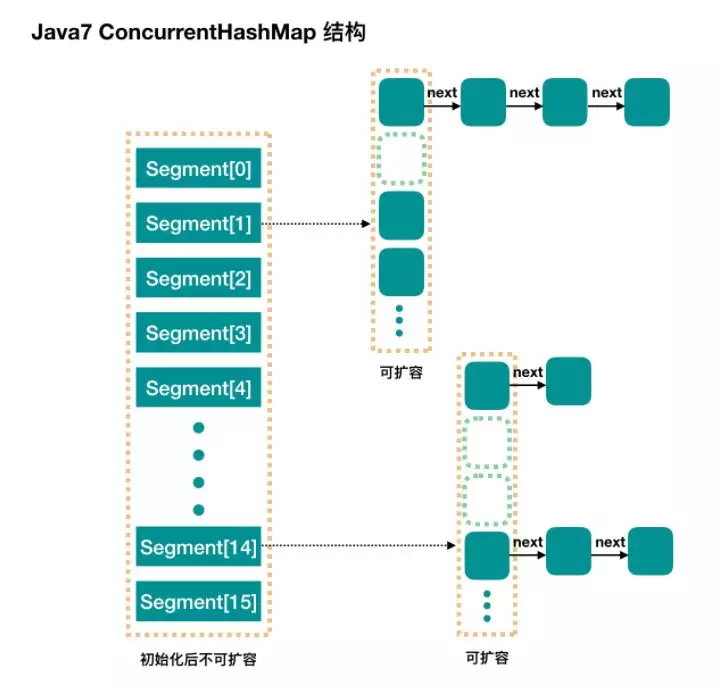
ConcurrentHashMap 中重要的属性
concurrencyLevel:默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的initialCapacity:初始容量,这个值指的是整个 ConcurrentHashMap 的初始容量,实际操作的时候需要平均分给每个 SegmentloadFactor:负载因子,之前我们说了,Segment 数组不可以扩容,所以这个负载因子是给每个 Segment 内部使用的
初始化
1 | // 这构造函数里,什么都不干 |
put 过程分析
1 | public V put(K key, V value) { |
初始化数组 :initTable
初始化方法中的并发问题是通过对 sizeCtl 进行一个 CAS 操作来控制的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 初始化的"功劳"被其他线程"抢去"了
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS 一下,将 sizeCtl 设置为 -1,代表抢到了锁
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
// DEFAULT_CAPACITY 默认初始容量是 16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 初始化数组,长度为 16 或初始化时提供的长度
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// 将这个数组赋值给 table,table 是 volatile 的
table = tab = nt;
// 如果 n 为 16 的话,那么这里 sc = 12
// 其实就是 0.75 * n
sc = n - (n >>> 2);
}
} finally {
// 设置 sizeCtl 为 sc,我们就当是 12 吧
sizeCtl = sc;
}
break;
}
}
return tab;
}
链表转红黑树 :treeifyBin
1 |
|
扩容:tryPresize
1 | // 首先要说明的是,方法参数 size 传进来的时候就已经翻了倍了 |
数据迁移:transfer
To do
get 过程分析
计算 hash 值
根据 hash 值找到数组对应位置: (n – 1) & h
根据该位置处结点性质进行相应查找
如果该位置为 null,那么直接返回 null 就可以了
如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
如果以上 3 条都不满足,那就是链表,进行遍历比对即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 判断头结点是否就是我们需要的节点
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 如果头结点的 hash 小于 0,说明 正在扩容,或者该位置是红黑树
else if (eh < 0)
// 参考 ForwardingNode.find(int h, Object k) 和 TreeBin.find(int h, Object k)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历链表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}